Query Guide¶
Here we provide a step-by-step guide for every query available, including an explanation of the output. Every query has an Example Query button at the bottom of the page. Try it out to see how a valid query would look like. Have a look at Results in detail to get an explanation of all the output parameters.
Gene Query¶
Do you wish to search for Regulatory Elements (REMs) related to a specific gene?
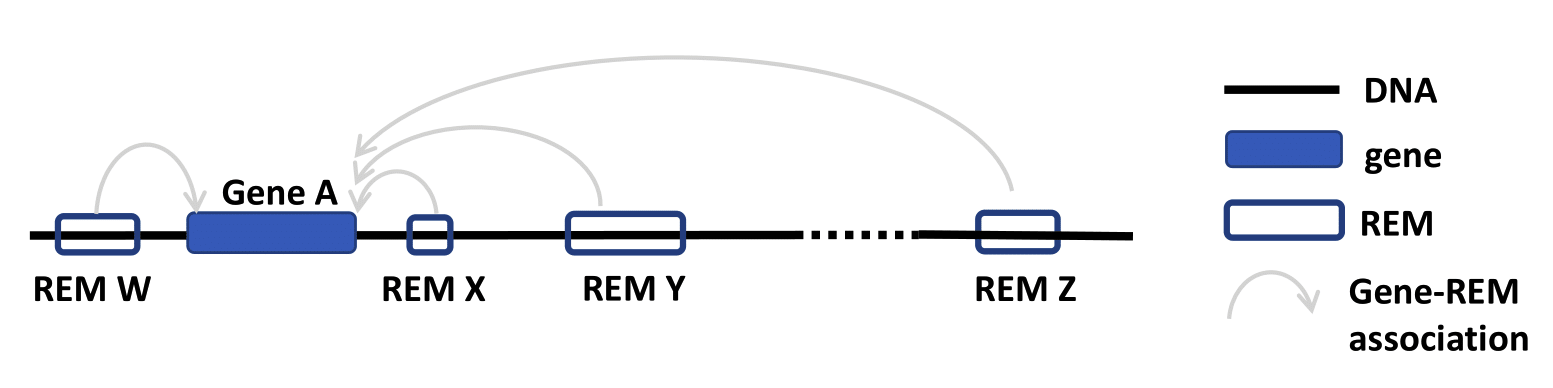
- Go to the Gene Query tab.
- You can choose to search either with gene symbol or ensembl ID. The version number of Ensembl IDs is not required. When entering gene symbols, you can add them from the suggestions appearing on the right by clicking on the buttons. Selected buttons will be listed underneath Currently selected:. Deselect your choices by reclicking on those buttons. We use the human genome version hg38.
- When you have multiple IDs or symbols to search, separate them by comma in the input field or create a csv- or txt-file and upload it. All of the commonly used separators are being recognized. A combination of both, the input field and the uploaded file, is not implemented.
- Choosing cell types/tissues: Start typing in the field Filter for cell types/tissues: the cell types of your interest, and suggesstions of available cell types matching your query will appear. To select a cell type, click on the button on the right. Cell types you write but do not select via a button click will not be considered for the query. To deselect click again on the button below Currently selected:. If your cell type does not appear, have a look at the Available cell and tissue types section and see whether you can find it there. Once you selected a cell type, a new input field will appear, which gives the option to choose an activity threshold. This threshold refers to the DNase activity of the REMs in the cell types/tissues. Only REMs that exceed the threshold in ALL of the cell types you selected will be shown in the output table. Leave the field empty to get back all REMs independent of their activity.

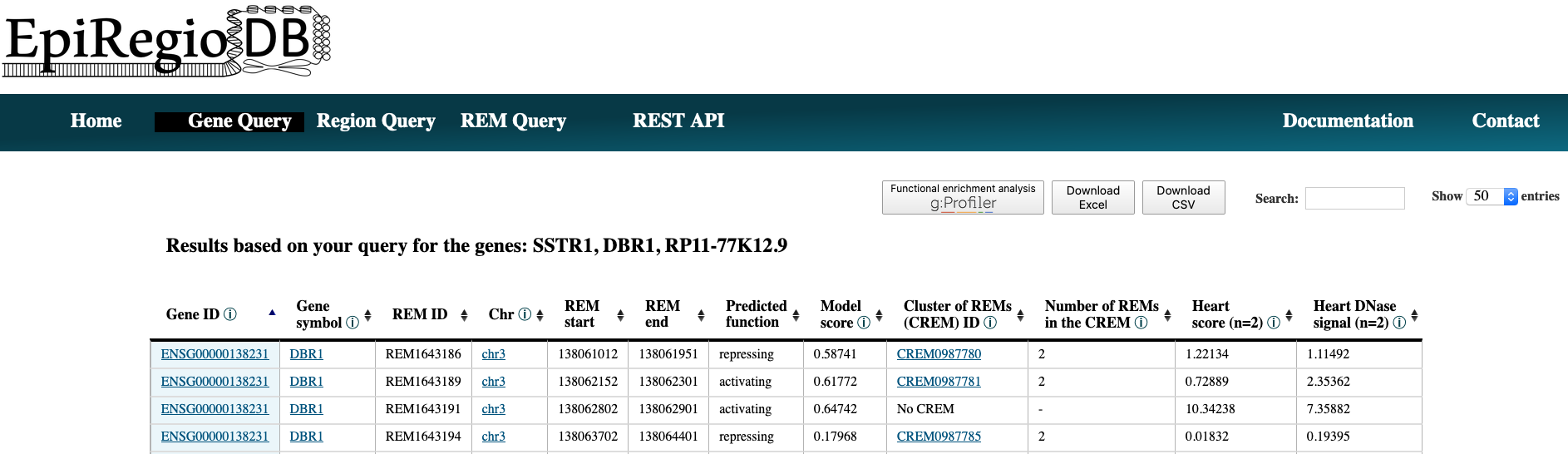
- The result page shows the information based on your query settings. All the REMs associated to your queried genes are listed with their location, their Predicted function, the Model score, the REM cluster they are belonging to and their activity in the cell types you selected. The Model score indicates how important a REM is for its associated gene over all cell types. The higher the value, the more important the REM is. The next column Cluster of REMs (CREM) ID contains the ID of the cluster this REM is contained in. A cluster of REMs consists of all the REMs that overlap by at least 1 bp. Click on a CREM ID to get to a table with all REMs of this CREM. We provide a more detailed description of CREMs here. If you selected cell types in your query, the Cell type score and the Cell type activity of the REMs in these cell types will be shown as average over all the samples n in the database (for each cell type separately, not averaged over all cell types). The Cell type score is the absolute product of the regression coefficient and the DNase activity, indicating how important a REM is in this cell type. The higher the value, the higher the REMs expected contribution to its gene’s expression in this cell type. Cell type activity is the DNase signal alone, indicating the chromatin accessibility in the REM region. If you need some more information on the genes themselves, click on the Gene ID to get to the respective Ensembl web page. By clicking on the Gene symbol you will receive a table with all REMs that are associated to the clicked gene. To see the REM region in the UCSC Genome Browser click on the chromosome entry. Another option is to use the ‘Functional enrichment analysis’ button to perform an analysis of all genes in the table with g:Profiler on default settings. You can export the table as xls- or csv-file. The downloaded file’s name is adapted to your query and contains the date as well as the current version of the website.
Region Query¶
Do you wish to search for Regulatory Elements (REMs) being located in a specific genomic region?
- Go to the Region Query tab.
- You can enter a region by choosing a chromosome, the start and the end point and then clicking on the Select button. Add as many regions as you like. Deselect your choices by reclicking on the added buttons. Only REMs that are located in your chosen regions will be given as output. You can select the percentage of overlap and by this define how much of the REM has to overlap with your selected regions to be shown in the output. For example, with an overlap of 50% only the REMs that overlap by at least half of their length with your selected regions will be returned.
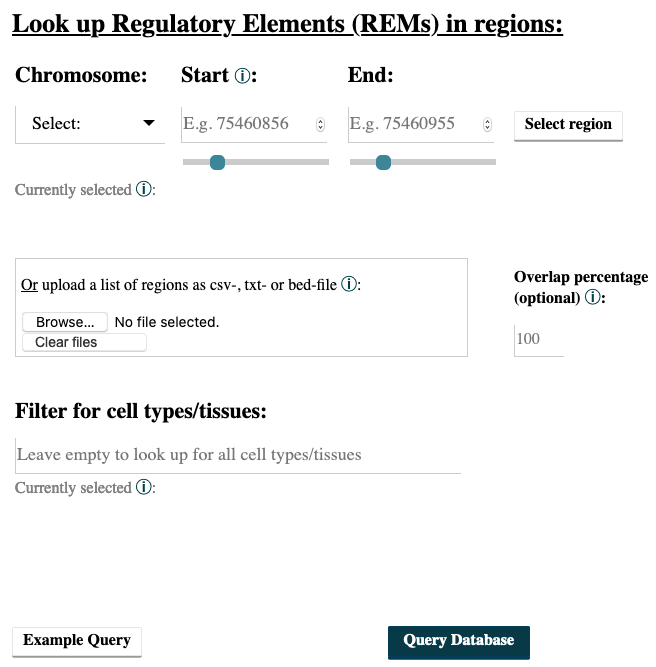
- You can also upload a csv-, txt- or bed-file with your regions of interest in which the first value has to be the chromosome, followed by the start and the end position. A combination of both, input field and uploaded file, is not implemented. You can see the format of exemplary upload files below (comma-separated and tab-separated). All of the commonly used separators are being recognized, as long as the order of chromosome, start position and end position is correct. For the bed-files, the columns have to be in the order chromsome, start position and end position as well. All additional columns beside of those first three ones will be ignored. Files with empty fields will not be read correctly.


- Choosing cell types/tissues: The selection of cell types functions in the same way as described above in the :href:`Gene Query` at point 4.
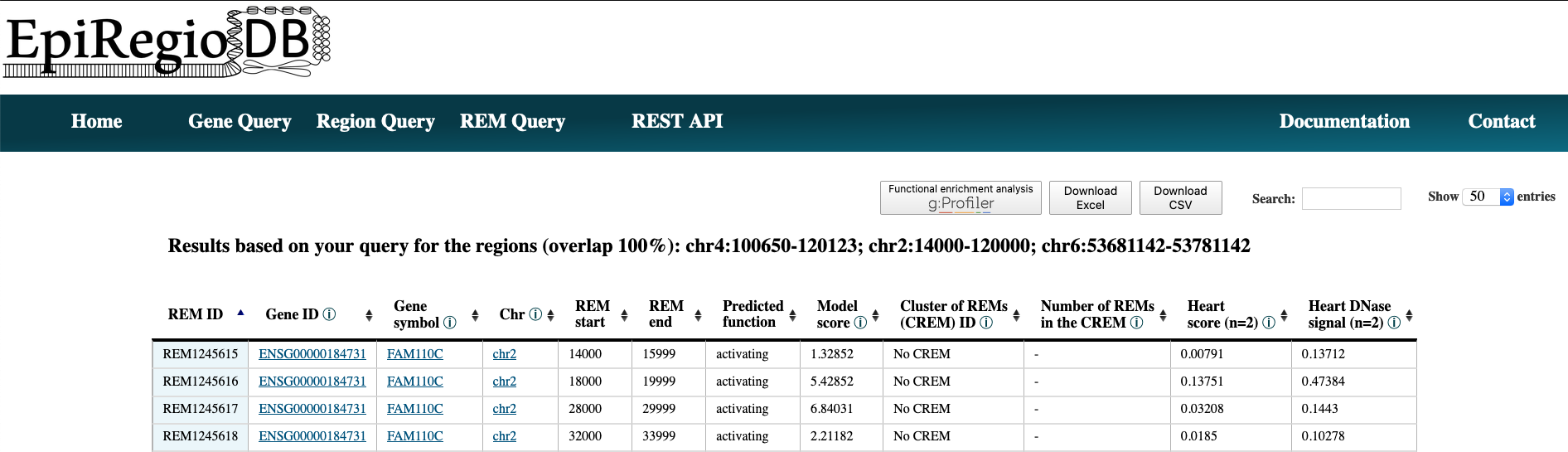
- The output is very similar for all queries. Have a look at point 5 of the :href:`Gene Query` or at the :href:`Results in detail`. Below you can see how the output of the Region query looks like.
REM Query¶
Do you wish to search for Regulatory Elements (REMs) by their ID?
- Go to the REM Query tab.
- Enter the IDs of your REMs of interest. Sepearte multiple ones by comma. You can upload a csv-file containing REM IDs. A combination of both, input field and uploaded file, is not implemented.
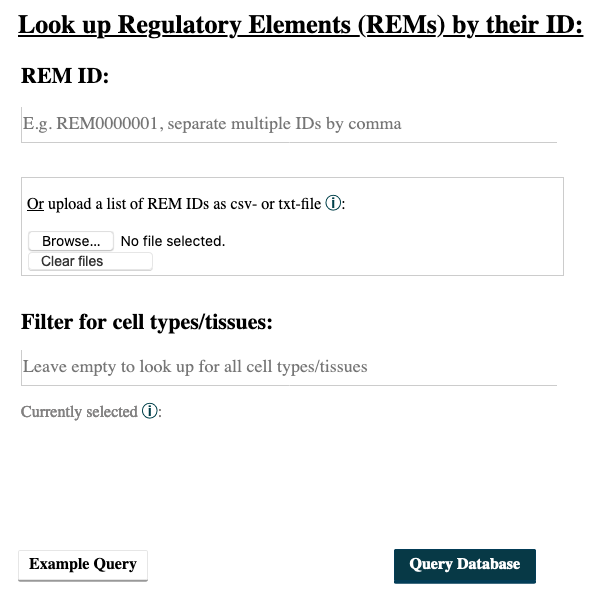
- Choosing cell types/tissues: The selection of cell types functions in the same way as described above in the :href:`Gene Query` at point 4.
- The output is very similar for all queries. Have a look at point 5 of the :href:`Gene Query` or at the :href:`Results in detail`. Below you can see how the output of the REM query looks like.
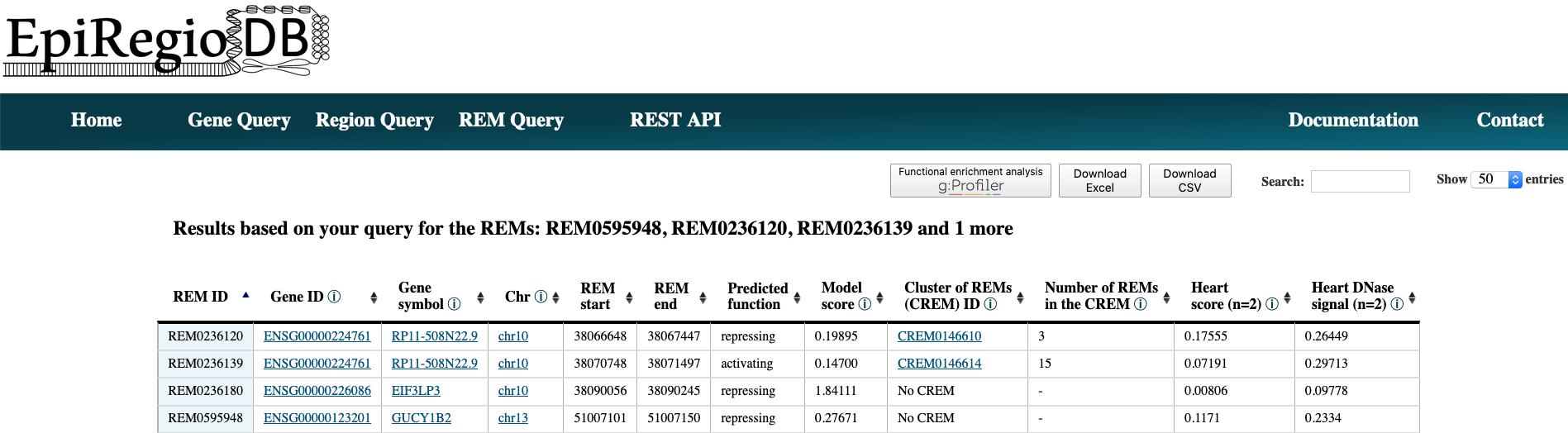
Interactive tables¶
All result tables possess additional functionalities like the possibility to filter for certain values or to sort the table by a selected column. Moreover, there are several links included. Each Gene ID in the tables is a link that gets you to the entry of this gene from the Ensembl genome browser. The entries in Gene symbol creates a new table with all the REMs that are associated to the clicked gene. Further, you can click on the chromosome value in a row to view the REM’s region inside of the UCSC Genome Browser. The values in the column Cluster of REMs (CREM) ID redirect you to a new table with all the REM contained in this cluster. In addition, the button ‘Functional enrichment analysis’ runs an analysis on all the genes currently in the table with g:Profiler on default settings.
Available cell and tissue types¶
In case you are wondering, whether your cell type or tissue is availale on EpiRegio, we list the available ones here. Every name is written as you would find it in the field where you filter for cell types (without the bullet point of course).
The following cell/tissue types are available from Roadmap. Please note that we list the cell/tissue type (biosample) names as listed in the ENCODE website, which also hosts the Roadmap data. :
|
|
|
From Blueprint we got the following cell types:
|
|
Results in detail¶
The tables you get from the different queries contain the same columns. Here you can get some more detailed information on each of them.
Gene ID and symbol¶
For the gene nomenclature we use the hg38 human genome version from the Ensembl Genome Browser. For each gene ID we have one gene symbol available. If a queried gene symbol is called to be invalid, try to use the ENSG ID (e.g. ENSG00000000001), as they are more definite.
REM ID¶
REM ID is how we define the REMs internally. Each REM ID is unique. Also the REMs, which have the exact same genomic region but are associated to different genes (happens rarly), are assigned to different REM IDs. We start counting from REM0000001 ascending.
Predicted function¶
STITCHIT identifies REMs by interpreting differential gene expression, meaning that a REM can be associated with an increase in gene expression as well as with a decrease. This association is represented by the regression coefficient. In case of a positive regression coefficient we assume an activating effect of the REM on its target gene’s expression and for a negative regression coefficient a repressing effect.
Model score¶
The Model score is the absolute binary logarithm of the p-value for the association between a REM and its target gene. It serves as an indicator on how important a REM is for the expression prediction of its target gene. The higher the score, the more impact the REM is supposed to have. This value is not cell type specific as it is calculated over all cell types. It allows for a comparison in between the REMs but not in between cell types. For a cell type-specific comparison, have a look at the Cell type score.
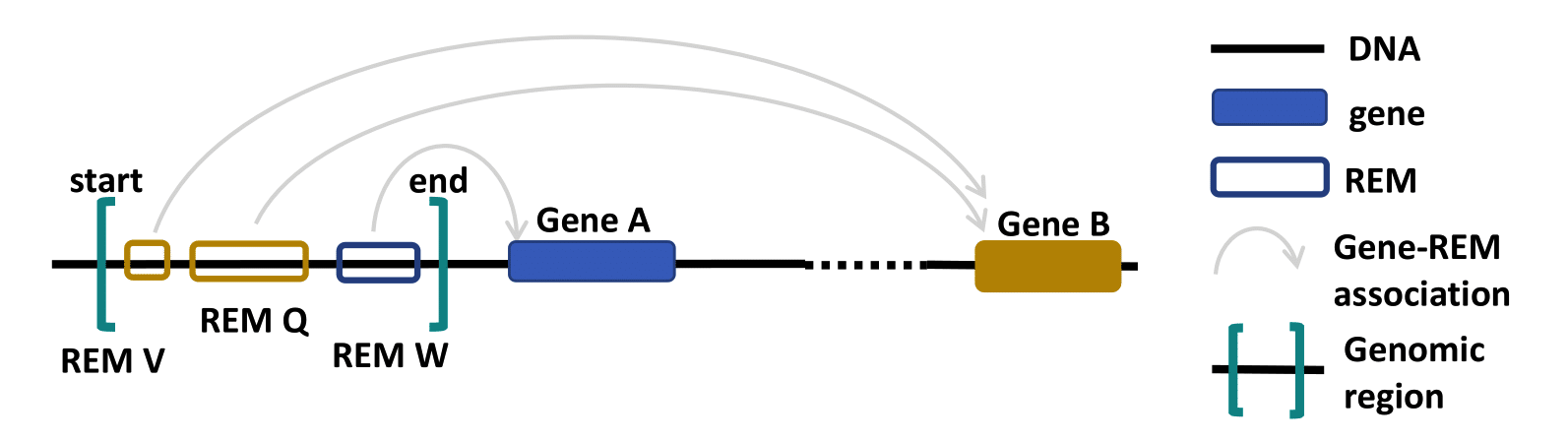
Cluster of REMs (CREM) ID¶
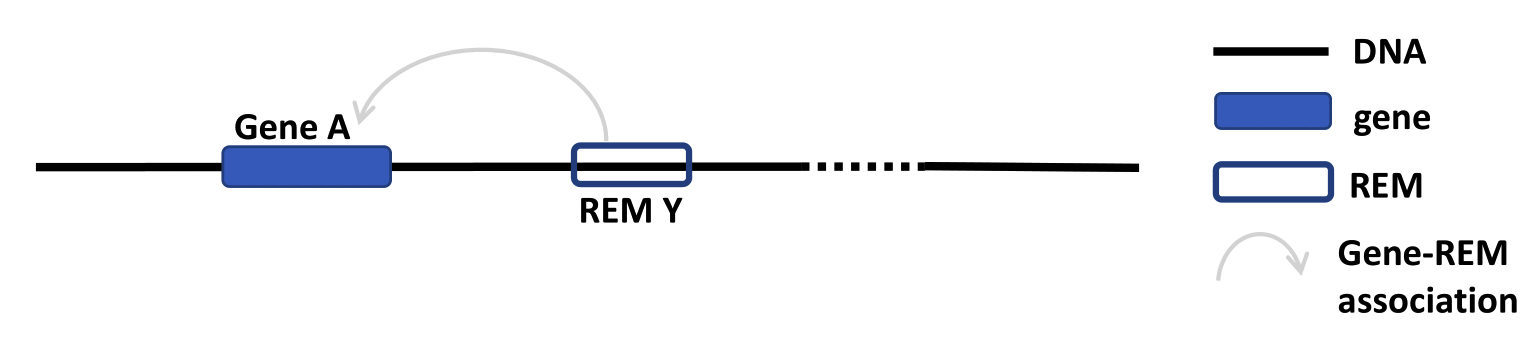
As STITCHIT determine REMs for each gene seperately and not the other way around, the identified regions can overlap. A REM cluster is a region of neighbouring REMs that overlap by at least one base pair (bp). There have to be a minimum of two overlapping REMs to be called a CREM. Each REM cluster is assigned to a unique CREM ID. We start counting from CREM0000001 ascending. By clicking on the Cluster of REMs (CREM) ID you get forwareded to a table with all REMs inside of this cluster. We show a schema of a CREM here.
Number of REMs per CREM¶
Shows how many REMs are contained in the CREM to which the REM belongs to. If the row is empty, then the REM does not have any overlapping other REM and therefore is not considered as a cluster.
Cell type score¶
Cell type score is the absolute product of the regression coefficient and the DNase1 activity in a REM, indicating how important a REM is in this cell type. The higher the value, the higher the REMs expected contribution to its target gene’s expression in this cell type. The regression coefficient is not cell type-specific, but the DNase1 activity is. Therefore, the Cell type score can be used to rank REMs according to their importance between cell types for the same gene or to rank REMs within one cell type.
Cell type DNase signal¶
Cell type DNase signal is the DNase1 signal for the cell type of interest measured in the REM region. It is normalized for sequening depth and can be used to compare the activity of REMs between samples. As we have more than one sample for each cell type, we took the average activity of those samples. The activity was obtained from the Roadmap and Blueprint consortia and is no parameter calculated by STITCHIT.